How to deploy application on Kubernetes with Helm
In this blog post I present step-by-step how to deploy multiple applications on Kubernetes cluster using Helm.
This is a second part of my series on Kubernetes. It compares three approaches of deploying applications:
- with kubectl — Deployment of multiple apps on Kubernetes cluster — Walkthrough
- with Helm — this one,
- with helmfile —How to declaratively run Helm charts using helmfile.
If you haven’t read it first one, I would advise to do that and then go back to this post. But if you prefer to jump right away to this post, don’t worry, I’ll briefly introduce you to the project.
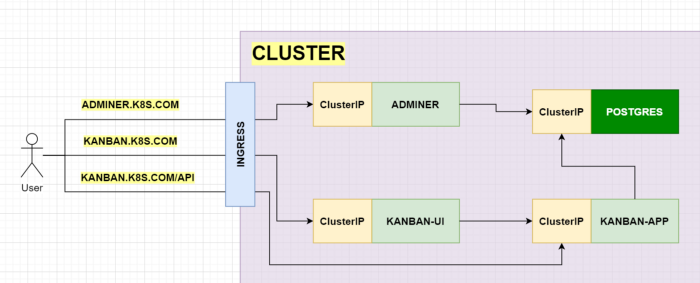
Above picture presents the target solution. Inside the cluster there will be deployed frontend (kanban-ui) and backend (kanban-app) services together with postgres database. A source code for both microservices can be found in my GitHub repository — kanban-board.
Additionally I’ve added an adminer, which is a GUI client for getting inside the database.
If we focus on one of services, e.g. on kanban-ui we can see that it needs to create two Kubernetes objects — ClusterIP & Deployment. With plain approach, using kubectl we would needed to create two files for each Kubernetes object:
The same story is for any other application — they need at least two definition files. Some of them requires even more, like postgres, which needs to have PersistentVolumeClaims defined in addition. As a result for even small project we can end up with lots of files which are very similar to each other:
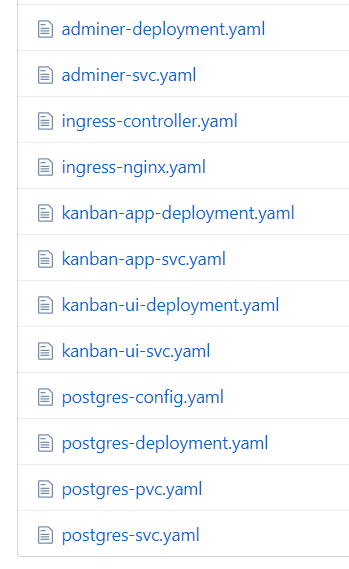
How to achieve the DRY in this case? Is it possible?
To reduce the number of YAML files we could merge them into one, for example, for kanban-ui it will look like this:
But it still doesn’t fix the major problem — how to avoid copy-pasting entire file just to replace couple of values? It would be great if there is a way to define a blueprint for both objects and then inject values into specific fields.
Luckily there is a solution! Helm to the rescue!
Accordingly to the official website — Helm is a package manager for Kubernetes. It helps deploy complex application by bundling necessary resources into Charts, which contains all information to run application on a cluster.
There are couple approaches how to work with Helm. One of them is to download publicly available charts from the Helm Hub. They are prepared by community and are free to use.
For instance, if we would like to run Prometheus on a cluster it would just easy as it’s described on this page — https://hub.helm.sh/charts/stable/prometheus — with the single command:
$ helm install stable/prometheusIt contains some default configuration, but can be easily overridden with YAML file and passed during installation. The detailed example I’ll show in a minute.
But Helm is not only providing some predefined blueprints, you can create your own charts!
It’s very easy and can be done by a single command helm create <chart-name> , which creates a folder with a basic structure:
$ helm create example
Creating example
In the templates/ folder there are Helm templates that with combination of values.yaml will result in set of Kubernetes objects.
Let’s create a first chart — postgres.
But just before that, boring installations and configurations (but promise, it’ll go quick). In my demo I’m using:
- Docker,
- locally installed Kubernetes cluster — minikube,
- Kubernetes command line tool — kubectl,
- Helm (v3).
When everything is installed you can start up the minikube cluster and enable ingress addon:
$ minikube start😄 minikube v1.8.1 on Ubuntu 18.04
✨ Automatically selected the docker driver
🔥 Creating Kubernetes in docker container with (CPUs=2) (8 available), Memory=2200MB (7826MB available) ...
🐳 Preparing Kubernetes v1.17.3 on Docker 19.03.2 ...
▪ kubeadm.pod-network-cidr=10.244.0.0/16
❌ Unable to load cached images: loading cached images: stat /home/wojtek/.minikube/cache/images/k8s.gcr.io/kube-proxy_v1.17.3: no such file or directory
🚀 Launching Kubernetes ...
🌟 Enabling addons: default-storageclass, storage-provisioner
⌛ Waiting for cluster to come online ...
🏄 Done! kubectl is now configured to use "minikube"$ minikube addons enable ingress
🌟 The 'ingress' addon is enabled
Then you’ll need to edit you hosts file. Its location varies on OS:
When you find it add following lines:
172.17.0.2 adminer.k8s.com
172.17.0.2 kanban.k8s.comTo make sure that this config is correct you’ll need to check if an IP address of minikube cluster on your machine is the same as it’s above. In order to do that run the command:
$ minikube ip
172.17.0.2Now we can create first Helm chart:
$ helm create postgres
Creating postgresWe will not need generated files inside ./templates folder, so remove them and also clear all the content inside values.yaml.
Now we can roll up our sleeves and define all necessary files to create chart for postgres database. For a reminder, in order to deploy it with kubectl we had to have following files:
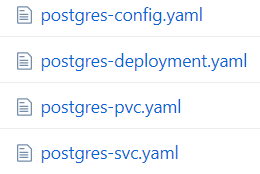
They contain definitions of ConfigMap, Deployment, PersistentVolumeClaim and ClusterIP. Their full definitions could be found in a repository.
First, let’s create a template for postgres Deployment object, therefore inside the ./templates create a deployment.yaml file:
At first glance you might see these strange parts between two pairs of curly brackets, like {{ .Values.postgres.name }} . They are written in Go template language and are referring to a value located in a values.yaml which is located inside the root folder of a chart. For mentioned example Helm will try to match it with a value from values.yaml:
postgres:
name: postgresAnother example. A value for a base Docker image, defined in image: {{ .Values.postgres.container.image }} will be taken from:
postgres:
name: postgres
container:
image: postgres:9.6-alpineAnd so on. We can define the structure inside this file whatever we like.
This database Deployment requires a PersistentVolumeClaim to be created to reserve some storage on a disk, therefore we need to create a Helm template — pvc.yaml inside ./templates folder:
This one is shorter, and there is nothing new here.
Next template that we need to create is for ClusterIP, which will allow other Pods inside the cluster to enter the Pod with postgres — service.yaml:
And finally ConfigMap template needs to be created — config.yaml. It’ll hold information about created database, user and its password (yes, not very secure, but for simple example it’s enough).
Here you might see a strange {{ -range ... }} clause, which can be translated as a for each loop known in any programming language. In above example, Helm template will try to inject values from an array defined in values.yaml:
postgres:
config:
data:
- key: key
value: valueInside a template, there are only dummy values. If you want to have different ones you would need to override them during installation of this set of objects on a Kubernetes cluster.
The entire values.yaml presents as follow:
replicaCount: 1postgres:
name: postgres
group: db
container:
image: postgres:9.6-alpine
port: 5432
service:
type: ClusterIP
port: 5432
volume:
name: postgres-storage
kind: PersistentVolumeClaim
mountPath: /var/lib/postgresql/data
pvc:
name: postgres-persistent-volume-claim
accessMode: ReadWriteOnce
storage: 4Gi
config:
name: postgres-config
data:
- key: key
value: value
To finalize creating first chart we need to modify some metadata inside Chart.yaml file:
Then create a new kanban-postgres.yaml file which will hold some specific values. Put it outside the postgres chart folder so the file structure can be similar to that:
Inside the file put only values that will be specific for this deployment, i.e. postgres database credentials (all other values we can keep as default):
postgres:
config:
data:
- key: POSTGRES_DB
value: kanban
- key: POSTGRES_USER
value: kanban
- key: POSTGRES_PASSWORD
value: kanbanEverything is set up, we can now deploy postgres into a cluster. In a Helm world this step is called creating a new release:
$ helm install -f kanban-postgres.yaml postgres ./postgres
NAME: postgres
LAST DEPLOYED: Mon Apr 13 16:13:16 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None$ helm list
NAME NAMESPACE REVISION STATUS CHART APP VERSION
postgres default 1 deployed postgres-0.1.0 1.16.0$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
postgres 1/1 1 1 2m14s
Cool, the postgres is up and running! Before moving forward let’s have a closer look on helm install command, what each of an argument means:

If you plan to use a chart only to create one Helm release you might wonder what is a value behind using Helm at all.
Let me show you that on another example. Let’s create a new chart called app — it will be a template chart for three different releases — adminer, kanban-app & kanban-ui.
$ helm create app
Creating appAfter removing unnecessary file from ./templates folder and cleaning the values.yaml create a deployment.yaml file:
Nothing new in particular, only some placeholders for values & two range loops to inject values from ConfigMaps or simple values to application container.
All 3 apps require to have also the ClusterIP objects to be deployed, therefore here is its template — service.yaml:
All default values in both templates are injected from values.yaml:
app:
name: app
group: app
replicaCount: 1
container:
image: add-image-here
port: 8080
config: []
env:
- key: key
value: value
service:
type: ClusterIP
port: 8080And to close a task of creating app chart — we need to define some metadata in the Chart.yaml file:
Then, similarly to previous example, outside the app folder create YAML files with values which will override ones from values.yaml inside app chart.
An adminer.yaml file looks as follow:
A kanban-app.yaml file:
A kanban-ui.yaml file:
A resulting file structure:
Now, in order to create three releases for each application use commands:
$ helm install -f adminer.yaml adminer ./app
NAME: adminer
LAST DEPLOYED: Mon Apr 13 16:57:17 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None$ helm install -f kanban-app.yaml kanban-app ./app
NAME: kanban-app
LAST DEPLOYED: Mon Apr 13 16:57:36 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None$ helm install -f kanban-ui.yaml kanban-ui ./app
NAME: kanban-ui
LAST DEPLOYED: Mon Apr 13 16:57:54 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None$ helm list
NAME NAMESPACE REVISION STATUS CHART APP VERSION
adminer default 1 deployed app-0.1.0 1.16.0
kanban-app default 1 deployed app-0.1.0 1.16.0
kanban-ui default 1 deployed app-0.1.0 1.16.0
postgres default 1 deployed postgres-0.1.0 1.16.0$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
adminer 1/1 1 1 112s
kanban-app 1/1 1 1 93s
kanban-ui 1/1 1 1 75s
postgres 1/1 1 1 45m
Perfect! There is one more thing to do — create a chart with Ingress Controller — a gateway to a cluster.
Like before, create a new chart:
$ helm create ingress
Creating ingressRemove all files from templates folder and clear content of values.yaml. This time, before moving straight away to defining a templates, let’s focus on to Chart.yaml first.
Here there is a new section — dependencies— which has been added. It creates default backend services which enables the Ingress Controller features.
But it’s not the only thing we need to do here. This section only defines on what this chart depends on, it won’t download it automatically during the installation. We need to take care of it ourselves. To do that run the command:
$ helm dependency update ./ingress/
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "stable" chart repository
Update Complete. ⎈Happy Helming!⎈
Saving 1 charts
Downloading nginx-ingress from repo https://kubernetes-charts.storage.googleapis.com/
Deleting outdated chartsInside the ingress/charts folder a new file will appear — nginx-ingress-1.36.0.tgz .
Now we can define a template for Ingress — it will be located inside ./templates folder and will be called ingress.yaml:
The most interesting part is inside specification section. There are two nested loops there which allow to define multiple hosts and multiple paths for each host.
And also, here is a default values.yaml file:
The resulting folder structure:
Outside the ingress chart we can now create an ingress.yaml file which will hold all routing rules for our cluster.
And now we’re able to create a Helm release:
$ helm install -f ingress.yaml ingress ./ingress
NAME: ingress
LAST DEPLOYED: Tue Apr 14 07:22:44 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None$ helm list
NAME NAMESPACE REVISION STATUS CHART APP VERSION
adminer default 1 deployed app-0.1.0 1.16.0
ingress default 1 deployed ingress-0.1.0 1.16.0
kanban-app default 1 deployed app-0.1.0 1.16.0
kanban-ui default 1 deployed app-0.1.0 1.16.0
postgres default 1 deployed postgres-0.1.0 1.16.0$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE
adminer 1/1 1 1
ingress-nginx-ingress-controller 1/1 1 1
ingress-nginx-ingress-default-backend 1/1 1 1
kanban-app 1/1 1 1
kanban-ui 1/1 1 1
postgres 1/1 1 1
Everything is set up, you can start testing it. Go to the http://kanban.k8s.com and you should get this page:

Congrats! 🍾🤘
Conclusions
In this short entry I’ve presented how, with Helm, you can reduce of copy-pasting tasks and can bring a one single template for deploying multiple applications on a Kubernetes cluster, which might be very handy in a microservice world. I hope you’ve enjoyed it.
But there is still one thing left, which holds us from establishing a fully declarative approach for an infrastructure. In order to deploy each application we still need to run imperative commands, like helm install. But luckily there is another tool — helmfile! But this one I’ll describe in my next story:
How to declaratively run Helm charts using helmfile
For now, here is my GitHub repository with a source code for this project:
And here is a source code of Kanban project:
